Four futures for the healthcare system
February 20, 2016 § 1 Comment
That healthcare systems the world over are under continual pressure to adapt is not in question. With continual concerns that current arrangements are not sustainable, researchers and policy makers must somehow make plans, allocate resources, and try to refashion delivery systems as best they can.
Such decision-making is almost invariably compromised. Politics makes it hard for any form of consensus to emerge, because political consensus leads to political disadvantage for at least one of the parties. Vested interests, whether commercial or professional, also reduce the likelihood that comprehensive change will occur.
Underlying these disagreements of purpose is a disagreement about the future. Different actors all wish to will different outcomes into existence, and their disagreement means that no particular one will ever arise. The additional confounder that predicting the future is notoriously hard seems to not enter the discussion at all.
One way to minimize disagreement and to build consensus would seem to be to have all parties come to a consensus of what the future is going to be like. With a common recognition of the nature of the future that will befall us, or that we aspire to, it might becomes possible to work backwards and agree on what must happen today.
Building different scenarios to describe the future
There seem to be two major determinants of the future. The first is the environment within which the health system has to function. The second is our willingness or ability to adapt the health system to meet any particular goal or challenge. Together these two axes generate four very different future scenarios. Each scenario has a very different set of challenges to it, and very different opportunities.
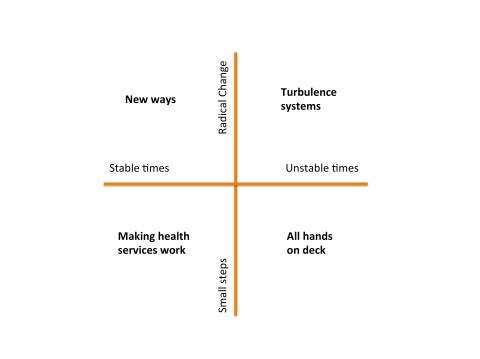
Making Health Services Work: In this quadrant, we are blessed with relatively stable conditions, and even though our capacity or will for change is modest, we can embark on incremental changes in response to projected future needs. We focus on gentle redesign of current health services, tweaking them as we need. The life of a heath services researcher is a comfortable one: no one needs or wants a revolution and there is time and resource enough to solve the problems of the day.
New Ways: Despite forgiving and stable times, in this quadrant we have an appetite for major change. Perhaps we see major changes ahead and recognize that incremental improvements will be insufficient to deal with them. Maybe we see future years with demographic challenges such as clinical workforce shortages and the increasing burden of disease associated with an ageing population. Consequently, more radical models of care are developed, evaluated and adopted. Rather than simply retro-fitting the way things are done, we radically reevaluate how things might be done, and envisage new ways of working, and conceive new ways to deliver services.
Turbulence systems: The risk of major shocks to the health system are ever present, including pandemics, weather events of ‘mass dimension’ associated with climate change, and human conflict. It is possible to make preparations for these unstable times. We might imagine that we set about to design some capacity for ‘turbulence’ management into our health services. Such turbulence systems would help us detect emerging shocks as early as possible, and would then reallocate resources as best we can when they arrive. The way that global responses to disease outbreaks has rapidly evolved over the last decade shows what is possible when our focus is on shock detection and response. Similar turbulence systems are evolving to respond to natural disasters and terrorism – so there are already models to learn from. In this quadrant then, we redesign the health system to be far more adaptive and flexible than it is today, recognizing that the future is not just going to be punctuated by rare external shocks, but that turbulence is the norm, and any system without shock absorbers will quickly shatter.
All hands on deck: In this scenario, health services receive major shocks in the near future, and well ahead of our ability to plan for these events. For example a series of major weather events or a new global pandemic could all stretch today’s health system beyond its capability to respond. Another route to this scenario in the long term is to not prepare for events like global warming or infectious disease outbreaks or an ageing population, and because of disagreement, underinvestment or poor planning, we do nothing. If such circumstances arrive, then the best thing that everyone in the health system can do is to abandon working on the long term, and apply our skills wherever they are most needed. In such crisis times, researchers will find themselves at the front lines, with a profound understanding and new respect for what implementation and translation really mean.
Picking a scenario
Which of these four worlds will we live in? It is likely that we have had the great good fortune over the last few decades of living in stable and reactively unambitious times, tinkering with a system that we have not had the appetite to change much. It seems likely that instability will increasingly become the norm however. I don’t think we will have the luxury of idly imagining some perfect but different future, debating its merits, and then starting to march toward it. There will be too much turbulence about to ever allow us the luxury of knowing exactly what the right system configuration will be. If we are very lucky, and very clever, we will increasingly redesign health services to be turbulence systems. Even if the flight to the future is a bumpy one, the stabilizers we create will help us keep the system doing what it is meant to do. ‘All hands on deck’ is the joker in the pack. I personally look forward to not ever having to work in this quadrant.
[These ideas were first published in a paper my team prepared back in 2007, and since it first appeared, the turbulence has slowly become more frequent …]
Evidence-based health informatics
February 11, 2016 § 6 Comments
Have we reached peak e-health yet?
Anyone who works in the e-health space lives in two contradictory universes.
The first universe is that of our exciting digital health future. This shiny gadget-laden paradise sees technology in harmony with the health system, which has become adaptive, personal, and effective. Diseases tumble under the onslaught of big data and miracle smart watches. Government, industry, clinicians and people off the street hold hands around the bonfire of innovation. Teeth are unfeasibly white wherever you look.
The second universe is Dickensian. It is the doomy world in which clinicians hide in shadows, forced to use clearly dysfunctional IT systems. Electronic health records take forever to use, and don’t fit clinical work practice. Health providers hide behind burning barricades when the clinicians revolt. Government bureaucrats in crisp suits dissemble in velvet-lined rooms, softly explaining the latest cost overrun, delay, or security breach. Our personal health files get passed by street urchins hand-to-hand on dirty thumbnail drives, until they end up in the clutches of Fagin like characters.
Both of these universes are real. We live in them every day. One is all upside, the other mostly down. We will have reached peak e-health the day that the downside exceeds the upside and stays there. Depending on who you are and what you read, for many clinicians, we have arrived at that point.
The laws of informatics
To understand why e-health often disappoints requires some perspective and distance. Informed observers again and again see the same pattern of large technology driven projects sucking up all the e-health oxygen and resources, and then failing to deliver. Clinicians see that the technology they can buy as a consumer is more beautiful and more useful that anything they encounter at work.
I remember a meeting I attended with Branko Cesnik. After a long presentation about a proposed new national e-health system, focusing entirely on technical standards and information architectures, Branko piped up: “Excuse me, but you’ve broken the first law of informatics”. What he meant was that the most basic premise for any clinical information system is that it exists to solve a clinical problem. If you start with the technology, and ignore the problem, you will fail.
There are many corollary informatics laws and principles. Never build a clinical system to solve a policy or administrative problem unless it is also solving a clinical problem. Technology is just one component of the socio-technical system, and building technology in isolation from that system just builds an isolated technology [3].
Breaking the laws of informatics
So, no e-health project starts in a vacuum of memory. Rarely do we need to design a system from first principles. We have many decades of experience to tell us what the right thing to do is. Many decades of what not to do sits on the shelf next to it. Next to these sits the discipline of health informatics itself. Whilst it borrows heavily from other disciplines, it has its own central reason to exist – the study of the health system, and of how to design ways of changing it for the better, supported by technology. Informatics has produced research in volume.
Yet today it would be fair to say that most people who work in the e-health space don’t know that this evidence exists, and if they know it does exist, they probably discount it. You might hear “N of 1” excuse making, which is the argument that the evidence “does not apply here because we are different” or “we will get it right where others have failed because we are smarter”. Sometimes system builders say that the only evidence that matters is their personal experience. We are engineers after all, and not scientists. What we need are tools, resources, a target and a deadline, not research.
Well, you are not different. You are building a complex intervention in a complex system, where causality is hard to understand, let alone control. While the details of your system might differ, from a complexity science perspective, each large e-health project ends up confronting the same class of nasty problem.
The results of ignoring evidence from the past are clear to see. If many of the clinical information systems I have seen were designed according to basic principles of human factors engineering, I would like to know what those principles are. If most of today’s clinical information systems are designed to minimize technology-induced harm and error, I will hold a party and retire, my life’s work done.
The basic laws of informatics exist, but they are rarely applied. Case histories are left in boxes under desks, rather than taught to practitioners. The great work of the informatics research community sits gathering digital dust in journals and conference proceedings, and does not inform much of what is built and used daily.
None of this story is new. Many other disciplines have faced identical challenges. The very name Evidence-based Medicine (EBM), for example, is a call to arms to move from anecdote and personal experience, towards research and data driven decision-making. I remember in the late ‘90s, as the EBM movement started (and it was as much a social movement as anything else), just how hard the push back was from the medical profession. The very name was an insult! EBM was devaluing the practical, rich daily experience of every doctor, who knew their patients ‘best’, and every patient was ‘different’ to those in the research trials. So, the evidence did not apply.
EBM remains a work in progress. All you need to do today is to see a map of clinical variation to understand that much of what is done remains without an evidence base to support it. Why is one kind of prosthetic hip joint used in one hospital, but a different one in another, especially given the differences in cost, hip failure and infection? Why does one developed country have high caesarian section rates when a comparable one does not? These are the result of pragmatic ‘engineering’ decisions by clinicians – to attack the solution to a clinical problem one way, and not another. I don’t think healthcare delivery is so different to informatics in that respect.
Is it time for evidence-based health informatics?
It is time we made the praxis of informatics evidence-based.
That means we should strive to see that every decision that is made about the selection, design, implementation and use of an informatics intervention is based on rigorously collected and analyzed data. We should choose the option that is most likely to succeed based on the very best evidence we have.
For this to happen, much needs to change in the way that research is conducted and communicated, and much needs to happen in the way that informatics is practiced as well:
- We will need to develop a rich understanding of the kinds of questions that informatics professionals ask every day;
- Where the evidence to answer a question exists, we need robust processes to synthesize and summarize that evidence into practitioner actionable form;
- Where the evidence does not exist and the question is important, then it is up to researchers to conduct the research that can provide the answer.
In EBM, there is a lovely notion that we need problem oriented evidence that matters (POEM) [1] (covered in some detail in Chapter 6 of The Guide to Health Informatics). It is easy enough to imagine the questions that can be answered with informatics POEMs:
- What is the safe limit to the number of medications I can show a clinician in a drop-down menu?
- I want to improve medication adherence in my Type 2 Diabetic patients. Is a text message reminder the most cost-effective solution?
- I want to reduce the time my docs spend documenting in clinic. What is the evidence that an EHR can reduce clinician documentation time?
- How gradually should I roll out the implementation of the new EHR in my hospital?
- What changes will I need to make to the workflow of my nursing staff if I implement this new medication management system?
EBM also emphasises that the answer to any question is never an absolute one based on the science, because the final decision is also shaped by patient preferences. A patient with cancer may choose a treatment that is less likely to cure them, because it is also less likely to have major side-effects, which is important given their other goals. The same obviously holds in evidence-based health informatics (EBHI).
The Challenges of EBHI
Making this vision come true would see some significant long term changes to the business of health informatics research and praxis:
- Questions: Practitioners will need develop a culture of seeking evidence to answer questions, and not simply do what they have always done, or their colleagues do. They will need to be clear about their own information needs, and to be trained to ask clear and answerable questions. There will need to be a concerted partnership between practitioners and researchers to understand what an answerable question looks like. EBM has a rich taxonomy of question types and the questions in informatics will be different, emphasizing engineering, organizational, and human factors issues amongst others. There will always be questions with no answer, and that is the time experience and judgment come to the fore. Even here though, analytic tools can help informaticians explore historical data to find the best historical evidence to support choices.
- Answers: The Cochrane Collaboration helped pioneer the development of robust processes of meta-analysis and systematic review, and the translation of these into knowledge products for clinicians. We will need to develop a new informatics knowledge translational profession that is responsible for understanding informatics questions, and finding methods to extract the most robust answers to them from the research literature and historical data. As much of this evidence does not typically come from randomised controlled trials, other methods than meta-analysis will be needed. Case libraries, which no doubt exist today, will be enhanced and shaped to support the EBHI enterprise. Because we are informaticians, we will clearly favor automated over manual ways of searching for, and summarizing, the research evidence [2]. We will also hopefully excel at developing the tools that practitioners use to frame their questions and get the answers they need. There are surely both public good and commercial drivers to support the creation of the knowledge products we need.
- Bringing implementation science to informatics: We know that informatics interventions are complex interventions in complex systems, and that the effect of these interventions vary depending on the organisational context. So, the practice of EBHI will of necessity see answers to questions being modified because of local context. I suspect that this will mean that one of the major research challenges to emerge from embracing EBHI is to develop robust and evidence-based methods to support localization or contextualisation of knowledge. While every context is no doubt unique, we should be able to draw upon the emerging lessons of implementation science to understand how to support local variation in a way that is most likely to see successful outcomes.
- Professionalization: Along with culture change would come changes to the way informatics professionals are accredited, and reaccredited. Continuing professional education is a foundation of the reaccreditation process, and provides a powerful opportunity for professionals to catch up with the major changes in science, and how those changes impact the way they should approach their work.
Conclusion
There comes a moment when surely it is time to declare that enough is enough. There is an unspoken crisis in e-health right now. The rhetoric of innovation, renewal, modernization and digitization make us all want to believers. The long and growing list of failed large-scale e-health projects, the uncomfortable silence that hangs when good people talk about the safety risks of technology, make some think that e-health is an ill-conceived if well intentioned moment in the evolution of modern health care. This does not have to be.
To avoid peak e-health we need to not just minimize the downside of what we do by avoiding mistakes. We also have to maximize the upside, and seize the transformative opportunities technology brings.
Everything I have seen in medicine’s journey to become evidence-based tells me that this will not be at all easy to accomplish, and that it will take decades. But until we do, the same mistakes will likely be rediscovered and remade.
We have the tools to create a different universe. What is needed is evidence, will, a culture of learning, and hard work. Less Dickens and dystopia. More Star Trek and utopia.
Further reading:
Since I wrote this blog a collection of important papers covering the important topic of how we evaluate health informatics and choose which technologies are fit for purpose has been published in the book Evidence-based Health Informatics.
References
- Slawson DC, Shaughnessy AF, Bennett JH. Becoming a medical information master: feeling good about not knowing everything. The Journal of Family Practice 1994;38(5):505-13
- Tsafnat G, Glasziou PP, Choong MK, et al. Systematic Review Automation Technologies. Systematic Reviews 2014;3(1):74
- Coiera E. Four rules for the reinvention of healthcare. BMJ 2004;328(7449):1197-99
An Italian translation of this article is available
A brief guide to the health informatics research literature
February 8, 2016 § Leave a comment
Every year the body of research evidence in health informatics grows. To stay on top of that research, you need to know where to look for research findings, and what the best quality sources of it are. If you are new to informatics, or don’t have research training, then you may not know where or how to look. This page is for you.
There are a large number of journals that publish only informatics research. Many mainstream health journals will also have an occasional (and important) informatics paper in them. Rather than collecting a long list of all of these possible sources, I’d like to offer the following set of resources as a ‘core’ to start with.
(There are many other very good health informatics journals, and their omission here is not meant to imply they are not also worthwhile. We just have to start somewhere. If you have suggestions for this page I really would welcome them, and I will do my best to update the list).
Texts
If you require an overview of the recent health informatics literature, especially if you are new to the area, then you really do need to sit down and read through one of the major textbooks in the area. These will outline the different areas of research, and summarise the recent state of the art.
I am of course biased and want you to read the Guide to Health Informatics.
A collection of important papers covering the important topic of how we evaluate health informatics and choose which technologies are fit for purpose can be found in the book Evidence-based Health Informatics.
Another text that has a well-earned reputation is Ted Shortliffe’s Biomedical Informatics.
Health Informatics sits on the shoulders of the information and computer sciences, psychology, sociology, management science and more. A mistake many make is to think that you can get a handle on these topics just from a health informatics text. You wont. Here are a few classic texts, from these ‘mother’ disciplines;
Computer networks (5th ed). Tannenbaum and Wetherall. Pearson. 2010.
Engineering Psychology & Human Performance (4th ed.). Wickens et al. Psychology Press. 2012.
Artificial Intelligence: A Modern Approach (3rd ed). Russell and Norvig. Pearson. 2013
Journals
Google Scholar: A major barrier to accessing the research literature is that much of it is trapped behind paywalls. Unless you work at a university and can access journals via the library, you will be asked by some publishers to pay an exorbitant fee to read even individual papers. Many journals are now however open-access, or make some of their papers available free on publication. Most journals also allow authors to freely place an early copy of a paper onto a university or other repository.
The most powerful way to finding these research articles is Google Scholar. Scholar does a great job of finding all the publicly available copies of a paper, even if the journal’s version is still behind a paywall. Getting yourself comfortable with using Scholar, and exploring what it does, provides you with a major tool for accessing the research literature.
Yearbook of Medical Informatics. The International Medical Informatics Association (IMIA) is the peak global academic body for health informatics and each year produces a summary of the ‘best’ of the last year’s research from the journals in the form of the Yearbook of Medical Informatics. The recent editions of the yearbook are all freely available online.
Next, I’d suggest the following ‘core’ journals for you to skim on a regular basis. Once you are familiar with these you will no doubt move on the the very many others that publish important informatics research.
JAMIA. The Journal of the American Medical Informatics Association (AMIA) is the peak general informatics journal, and a great place to keep tabs on recent trends. While it requires a subscription, all articles are placed into open access 12 months after publication (so you can find them using Scholar) and several articles every month are free. You can keep abreast of papers as they are published through the advanced access page.
JMIR. The Journal of Medical Internet Research is a high impact specialist journal focusing on Web-based informatics interventions. It is open access which means that all articles are free.
To round out the journals you might want to add into your regular research scan the following journals which are all very well regarded.
- Journal of Biomedical Informatics, which focuses more on methods than the other journals.
- International Journal of Medical Informatics, which tries to cover informatics issues with a global perspective.
- Artificial Intelligence in Medicine, which as the name suggest is focussed on advance topics in decision support and analytics.
- BMC Medical Informatics and Decision Making, which is an open access member of the BMC family of journals
- Methods of Information in Medicine, specialises in informatics methodologies.
Conferences
Whilst journals typically will publish well polished work, there is often a lag of a year or more before submitted papers are published. The advantage of research conferences is that you get more recent work, sometimes at an earlier stages of development, but also closer to the cutting edge.
There are a plethora of informatics conferences internationally but the following publish their papers freely online, and are typically of high quality.
AMIA Annual Symposium. AMIA holds what is probably the most prestigious annual health informatics conference, and releases all papers via NLM. An associated AMIA Summit on Translational Sciences/Bioinformatics is also freely available.
Medinfo. IMIA holds a biannual international conference, and given its status as the peak global academic society, Medinfo papers have a truly international flavour. Papers are open access and made available by IOS press through its Studies in Health Technology and Informatics series (where many other free proceedings can be found). Recent Medinfo proceedings include 2015 and 2013.
As with textbooks and journals, it is worth remembering that much of importance to health informatics is published in other ‘mother’ disciplines. For example it is well worth keeping abreast of the following conferences for recent progress:
WWW conference. The World Wide Web Conference is organised by the ACM and is an annual conference looking at innovations in the Internet space. Recent proceedings include 2015 and 2014.
The ACM Digital Library, which contains WWW, is a cornucopia of information and computer science conference proceedings. Many a rainy weekend can be wasted browsing here. You may need to hunt the web site of the actual conference however to get free access to papers as ACM will often try to charge for papers you can find freely on the home page of the conference.
Other strategies
Browsing journals is one way to keep up to date. The other is to follow the work of individual researchers whose interests mirror your own. The easiest way to do this is to find their personal page on Google Scholar (and if they don’t have one tell them to make one!). Here is mine, as an example. There are two basic ways to attack a scholar page. When you first see a Scholar page, the papers are ranked by their impact (as measured by other people citing the papers). This will give you a feeling about the work the researcher is most noted for. The second way is to click the year button. You will then see papers in date order, starting with the most recent. This is a terrific way of seeing what your pet researcher has been up to lately.
There is a regularly updated list of biomedical informatics researchers, ranked by citation impact, and this is a great way to discover health informatics scientists. Remember that when researchers work in more specialised fields, they may not have as many citations and so be lower down the list.
Once you find a few favourite researchers, try to see what they have done recently, follow them on Twitter, and if they have a blog, try to read it.
